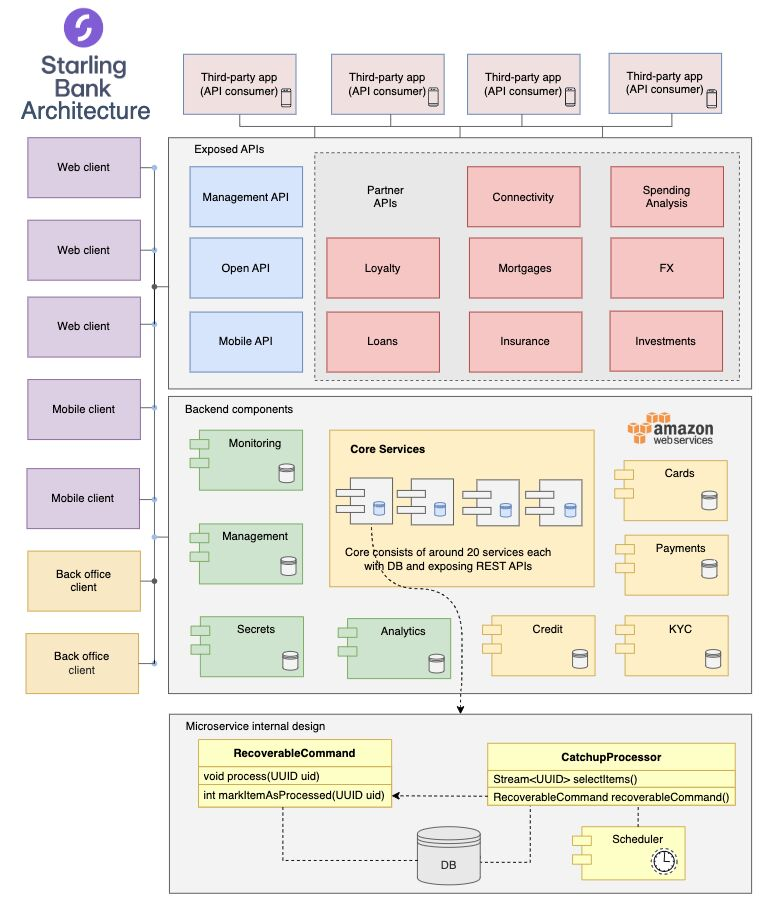
Architecture of a neobank – Starling Bank
Starling Bank is the third largest – after Revolut and Monzo – among those digital banks referred to as challenger banks or neobanks in the UK. Starling Bank is a 100% cloud-based, mobile-only digital bank with a modern architecture designed based on the best practices in security, reliability, and resilience. It provides fintech developers with innovative APIs for account opening, payments, loans, etc., as well as a developer platform, custom backend ledger, and functionality for integration with Apple Pay and Google Pay.
The architecture of Starling Bank is based on the following principles:
1. Microservice architecture
2. Do everything at least once at most once
3. Async + Idempotence + Retry
4. Each service constantly working towards correctness
5. Often achieve Idempotence by immutability
6. No distributed transactions
7. Don’t trust other services
Backend technology stack
1. Java services in Docker and CoreOS
2. AWS: EC2, VPC, CloudFormation
3. REST (JAX-RS)
4. PostgreSQL
5. Jetty, Guice, Guava, Hystrix
6. Homegrown libraries: SQL database access layer, configuration, command line, background processing
7. No Spring, no JEE app servers, no Kubernetes, no Terraform
8. Prometheus for monitoring
9. ELK for log aggregation
10.PagerDuty for incident alerting
Builds and deployments
1. Continuous deployment to non-prod, sign off into prod
2. Auto build, dockerize, test, scan, deploy < 1 hr
3. Code release to production up to 5 times a day
4. Single stateless service per instance
5. Rolling deployments by termination
An interesting question is: How do they achieve data consistency without transactions? The answer is that they use an approach in which each microservice constantly works towards data consistency. In this way, the system implements eventual consistency. It is acceptable in most cases, except for card transactions, for which it is important to know the correct, up-to-date balance when a customer is about to use a card. To guarantee data consistency, they use two patterns, which are at the foundation of this architecture:
1. Recoverable Command
2. Catch-up processor
public interface RecoverableCommand{
void process(UUID uid);
int markItemAsProcessed(UUID uid);
}
public abstract class CatchupProcessor implements Runnable{
protected abstract Stream<UUID> selectItems();
protected abstract RecoverableCommand recoverableCommand();
}
If a microservice fails to execute a command, the catch-up processor will try to re-execute it and fix the data. They both work with object ID parameters while the context data is stored in the DB. Catch-up processing gets triggered by the scheduler every 5 minutes. This approach makes microservices stateless and resilient. An EC2 instance with a stateless microservice can be safely restarted at any moment, which is critical for resilience and scalability.